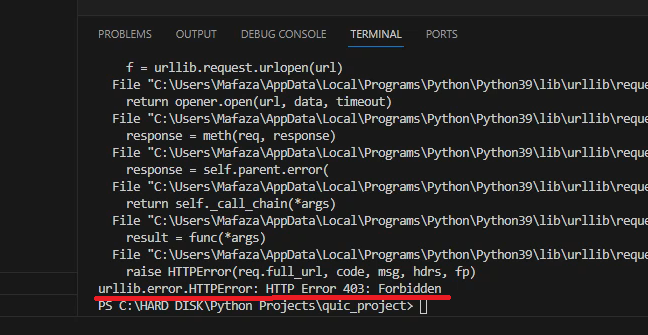
CODE:
import urllib.request url = 'https://stackoverflow.com/questions/27673870/cant-create-pdf-using-python-pdfkit-error-no-wkhtmltopdf-executable-found' f = urllib.request.urlopen(url) myfile = f.read() print(myfile)
SOLUTION:
The urllib.request module is used to construct HTTP request that can be passed to the urlopen() function.
import urllib.request request = urllib.request.Request(url = 'https://stackoverflow.com/questions/27673870/cant-create-pdf-using-python-pdfkit-error-no-wkhtmltopdf-executable-found', headers={'User-Agent': 'Mozilla/5.0'}) f = urllib.request.urlopen(request) myfile = f.read() print(myfile)