
I got this following error while try to scrap a website using URL in python.
"urllib.error.HTTPError: HTTP Error 403: Forbidden"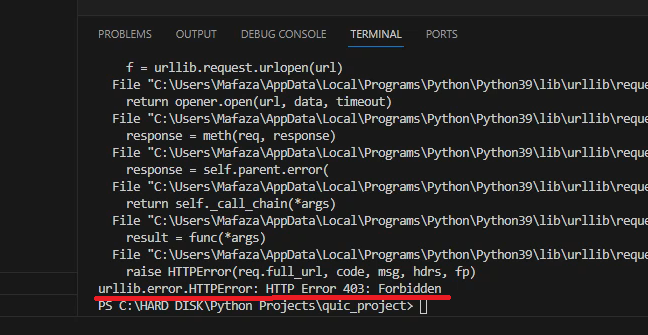
CODE:
import urllib.request url = 'https://stackoverflow.com/questions/27673870/cant-create-pdf-using-python-pdfkit-error-no-wkhtmltopdf-executable-found' f = urllib.request.urlopen(url) myfile = f.read() print(myfile)
SOLUTION:
The urllib.request module is used to construct HTTP request that can be passed to the urlopen() function.
import urllib.request request = urllib.request.Request(url = 'https://stackoverflow.com/questions/27673870/cant-create-pdf-using-python-pdfkit-error-no-wkhtmltopdf-executable-found', headers={'User-Agent': 'Mozilla/5.0'}) f = urllib.request.urlopen(request) myfile = f.read() print(myfile)
VIDEO GUIDE:
Post your comments / questions
Recent Article
- How to create custom 404 error page in Django?
- Requested setting INSTALLED_APPS, but settings are not configured. You must either define..
- ValueError:All arrays must be of the same length - Python
- Check hostname requires server hostname - SOLVED
- How to restrict access to the page Access only for logged user in Django
- Migration admin.0001_initial is applied before its dependency admin.0001_initial on database default
- Add or change a related_name argument to the definition for 'auth.User.groups' or 'DriverUser.groups'. -Django ERROR
- Addition of two numbers in django python
Related Article